
„Hudba je univerzální řeč lidstva,“ napsal, do značné míry metaforicky, americký básník H. W. Longfellow, kterého známe především jako autora eposu Píseň o Hiawathovi. Lze ale vzít básníka za slovo a hudbu univerzálně a digitálně kódovat?
V současnosti se na světě vyskytuje přibližně 7 000 mluvených jazyků. Ačkoli pouze desetinou z nich mluví více než 100 000 lidí, stále se mezi jednotlivými kulturami objevuje značná komunikační mezera. Existuje ovšem jeden jazyk, kterému každý rozumí bez ohledu na to, jakou řečí mluví: hudba. Přestože třeba nerozumíme textům zahraničních písní, loňská studie s názvem Universality and Diversity in Human Song, jež byla prezentována v časopise Science, mimo jiné zjistila, že si lidé z odlišných kultur dokážou jako reakci na vybrané akordy či melodie vybavit obdobné emoce.
Ať patříte mezi 320 milionů aktivních uživatelů platformy Spotify nebo si jen přehráváte písně ze svého oblíbeného uložiště, jedno je jisté: digitální forma skladeb má v dnešním světě nezastupitelné místo. Mnozí konzumenti ovšem nevyhledají kulturní zážitek nebo potěšení z uměleckých děl, nýbrž spíše soundtrack pro dlouhé hodiny cestování, čekání či jako zvukovou kulisu, zatímco se věnují práci nebo odpočinku. V neposlední řadě hudební průmysl tlačí k nepřetržité produkci nových hudebních děl, zejména v žánrech jako jsou pop a rock. Právě dostupnost takto ohromného množství obsahu nás vede k myšlence, zdali i kulturní oblasti nelze jakýmsi způsobem automatizovat. Big data nám umožnila generovat texty novinových článků, vybrat si nejlevnějšího prodejce letenek či předpovídat ceny akcií. Proč by to v případě algoritmické kompozice mělo být jiné?
Hudba jako formální jazyk?
Ačkoliv to může znít jako klišé, hudba a jazyk mají více společného, než se může na první pohled zdát; alespoň tedy z pohledu počítače. Nejpřímějším vyjádřením digitálních skladeb libovolného formátu je ovšem surový zvukový signál, ve kterém osa x představuje čas a osa y amplitudu signálu – viz obrázek.
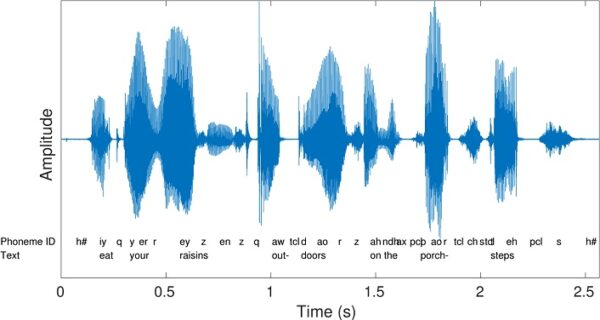
Problém nastává v situaci, kdy chceme skladbu pro potřeby strojového učení rozložit na binární kód, tedy sadu jedniček a nul. V cestě stojí hned několik problémů: zprvu, audio signál je ve své nejhlubší podstatě signálem spojitým. Této překážce se sice u digitálních formátů lze vyhnout pomocí techniky vzorkování, jež spojitou funkci převádí na diskrétní, a tedy bitově rozložitelný signál, zpracování nízkoúrovňového audio formátu je ovšem neuvěřitelně náročné, a to nejen z hlediska výpočetního výkonu, ale i z důvodu nutného formátování, normalizace či sekvenčního zpracování. Proto – stejně jako v případě jazyka – vznikla nutnost zavést vhodnou reprezentaci, jež by se inspirovala lingvististicko-antropologickým vztahem, jaký můžeme pozorovat mezi řečí a písmem.
Řešení je nasnadě: tuto funkci již od nepaměti zastává notace. Záznam pomocí notového zápisu je příkladem takzvané reprezentace znalostí, která na rozdíl od surového audio signálu pracuje s vágnější transkripcí skladeb. Tradiční hudební partituru lze považovat za sadu symbolů, jež jsou uspořádány v časové posloupnosti, představující hudební entity, jako jsou noty, trvání a výšky tónů. Všechny instrukce v partituře jsou symbolickými reprezentacemi pokynů, jež označují kroky, které musí muzikant provést, aby mohl hudbu přehrát. Hlavní výhodou této metody je definovaný formalismus reprezentace a implementace: záznam lze pozorovat, ověřovat jeho pravidla, studovat, upravovat či rozšiřovat samotné dílo. Nejedná se o nečitelné černé skříňky, ale spíše o formální jazyk, kterému můžeme porozumět nejen my, ale i stroje.
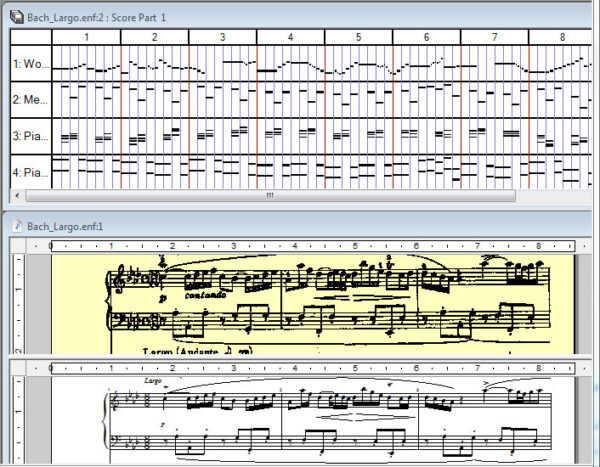
Znázornění skladeb pomocí symbolů taktéž významně usnadňuje jejich zpracování pomocí strojového učení, hledá totiž podstatu písní v pouhém kompozičním procesu, zatímco zanedbává definování specifik nástrojů a přispění muzikantů. Eduardo Reck Miranda, hudební skladatel a jeden z průkopníků moderní algoritmické kompozice, se ve své knize Multilevel Music Knowledge Representation and Programming domnívá, že právě vytvoření vhodného nástroje pro reprezentaci znalostí je základem pro úspěšný vývoj modelů na bázi umělé inteligence. Ačkoli je tradiční partitura nepochybně nadčasovým formátem zápisu, skutečné hudební znalosti často přesahují hranice tradiční notové osnovy. Reálné příklady zahrnují prvky a entity, pravidla a omezení, úmyslné postupy a tvůrčí přerušení vzorů a pravidel. Vhodná reprezentace by tedy měla být schopna zaznamenat každou úroveň kompozice: od skladatelovy abstrakce po akustickou složku. Z tohoto paradigmatu vzešel i populární formát SMF (Standard MIDI File – obr. výše), jež nepochybně ovlivnil vývoj počítačové hudby. Formát SMF se stal standardem pro přenos dat mezi uživateli: ačkoli je flexibilní a jednoduchý, poskytuje koherentní zastoupení na různých, ne ovšem na všech úrovních.
Dolování znalostí z hudebních souborů
Přestože je strojové učení vysoce efektivní při zpracování nestrukturovaných dat, ze kterých získává hierarchii vrstev reprezentace vyšší úrovně, některé systémy obsahují předběžnou automatickou extrakci, aby byla data reprezentována v kompaktnější, charakteristické a diskriminační formě. Zvyšující se dostupnost hudby v digitálním formátu musí odpovídat vývoji nástrojů pro přístup k hudbě, její filtrování, klasifikaci a vyhledávání. V posledních letech nabývá na významu interdisciplinární obor Music Information Retrieval, taktéž známý pod zkratkou MIR, který mísí zdánlivě neprolínající se okruhy muzikologie, strojového učení a zpracování signálu. Metody datové extrakce spadající pod tuto mladou doménu jsou důležitým předpokladem pro rozvoj algoritmické kompozice na bázi strojového učení. Jak ale takové získávání informací probíhá?
Jednou z nejpopulárnějších současných metod je extrakce příznaků, jež má za úkol redukovat dimenzionalitu dat. Díky tomu je tzv. content-based model schopen extrahovat pouze prvky, které považuje za důležité, zatímco ignoruje ty, jež jsou pro náš cíl redundantní. Aby ovšem byla data dále zpracovatelná pomocí strojového učení, je nutné přiřadit jednotlivým entitám jednoduché symboly, které nazýváme tokeny. Tyto tokeny, stejně jako v případě klasické notace, mohou značit noty, trvání či výšky tónů, čímž dochází k extrémní kompresi znalostí: namísto spojitého signálu, který sdružuje soubor velikosti desítek MB získáváme symbolickou extrakci o velikosti několika stovek bitů. Skvělým příkladem redukovaného datového záznamu je ABC notace, jež nalezla využití nejen v rámci archivace tradiční irské hudby, kde v 80. letech zaznamenala své hlavní využití. Zápis ABC je založen na ASCII znacích a ke zpracování kódu lze použít libovolný textový editor. Právě tato vlastnost je důležitá pro usnadnění aplikace strojového učení, kdy se každý jednotlivý token stává nositelem významné hudební informace. I zde lze pozorovat blízkou podobnost se zpracováním jazykových korpusů, snad jen s tím rozdílem, že v rámci lingvistické extrakce pracujeme se shlukem symbolů, jež pouze po splynutí do vyšších entit vykazují vlastní smysl, ať již v podobě slov či vět.
Samozřejmě, domnívat se, že vztah mezi hudbou a jazykem lze popsat pomocí několika analogických formulí, je až romanticky naivní. Přesto expertům, zabývající se algoritmickou kompozicí a generativními modely, usnadňují tyto podobnosti každodenní práci. Od korpusové analýzy, přes augmentaci datasetu, až po dolování informací: tam všude můžeme pozorovat až neobvykle se opakující vzory, jež hudbu i jazyk doprovází již od raných časů.